
December 2025 - Use of Nano Banana Pro for geospatial concepting
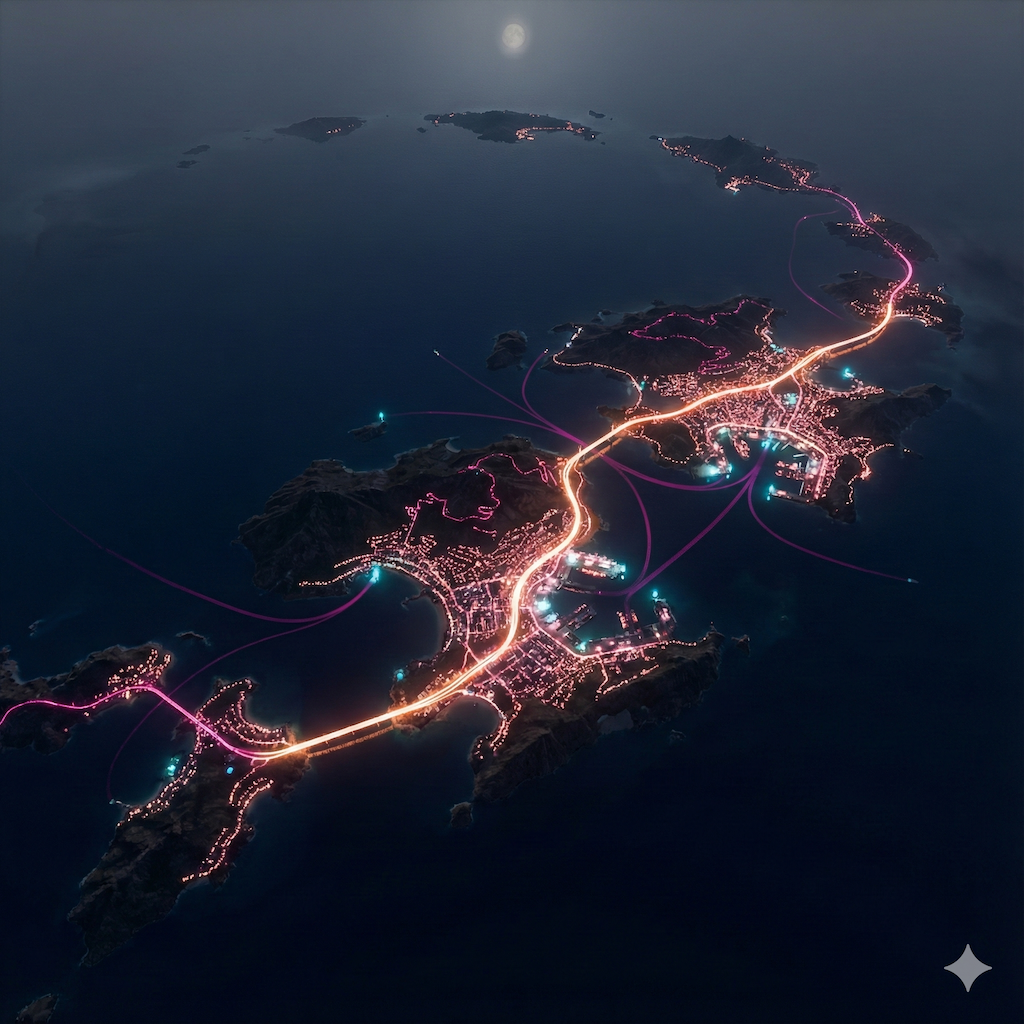
I am working on a large scale data visualization of city/urban/country data (potentially using platforms like Mapbox, Blender and other tools). To anticipate on what it could look like, I spent some time prototyping some looks (largely on roads and city look from different angles and altitude). These are some of the shots. These shots have not been post-processed and are straight out of Nano Banana Pro (with the help of ChatGPT 5.1 Deep Thinking for advanced prompting).
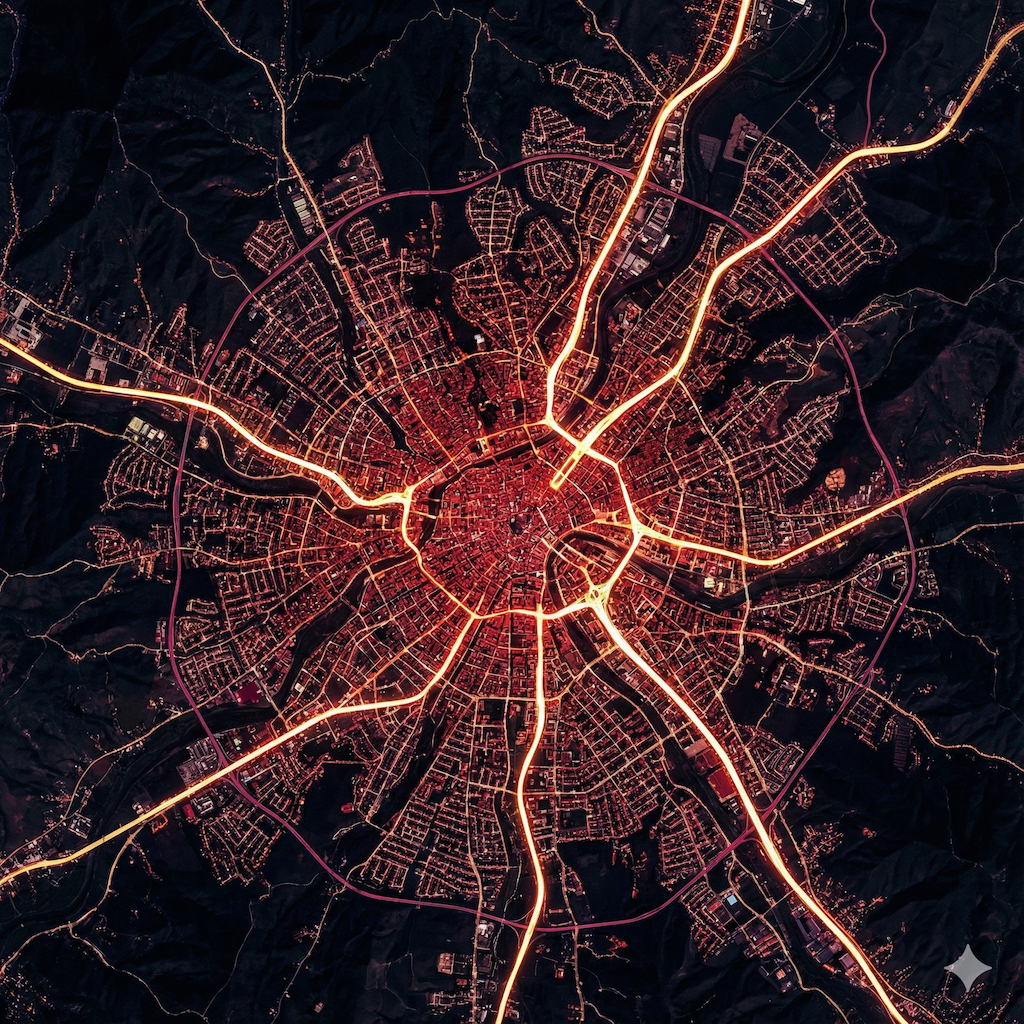
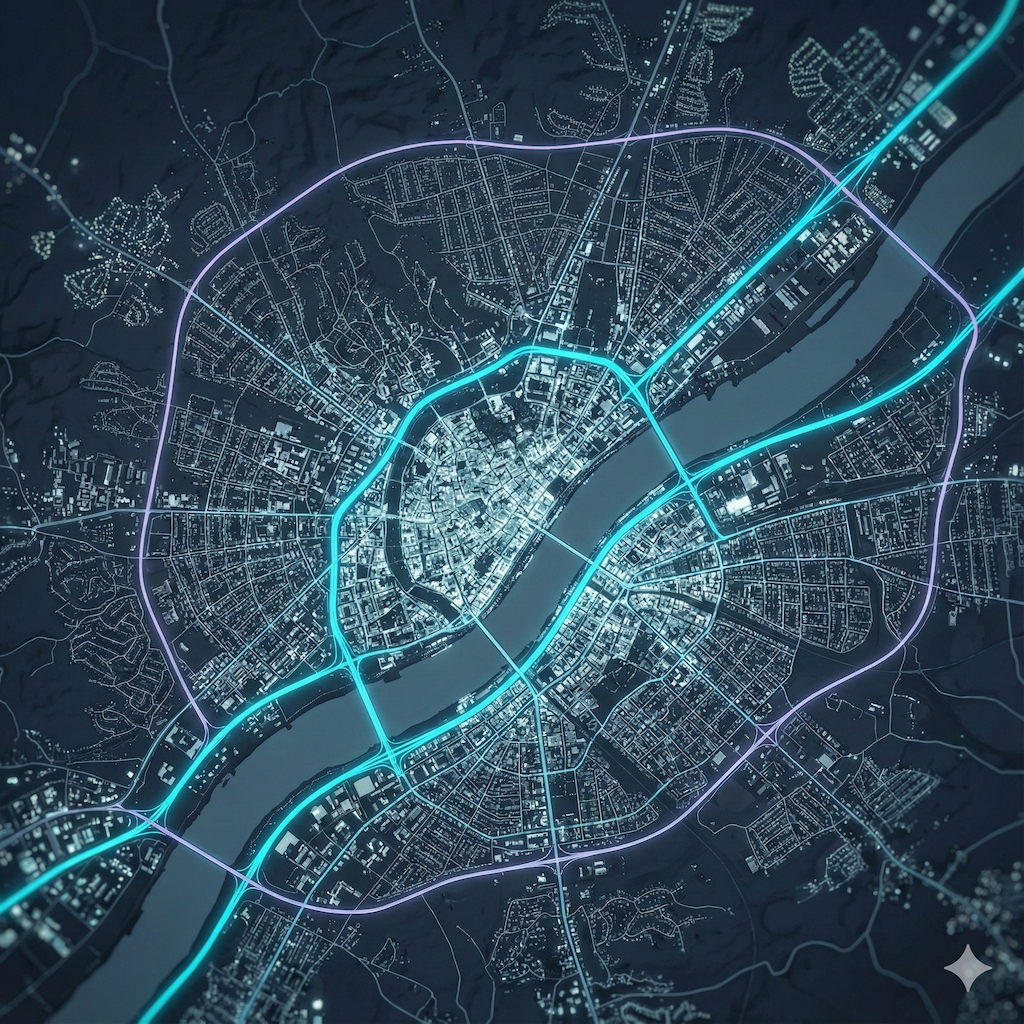

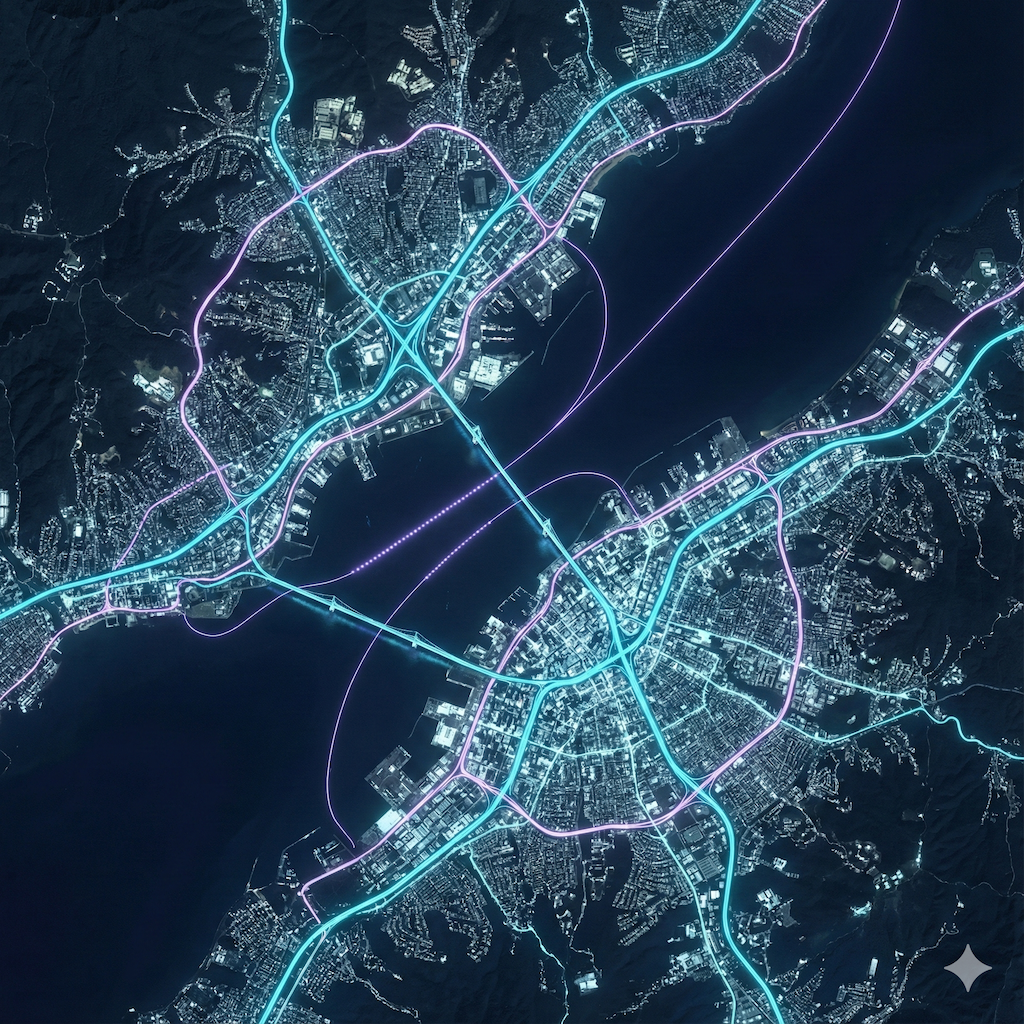
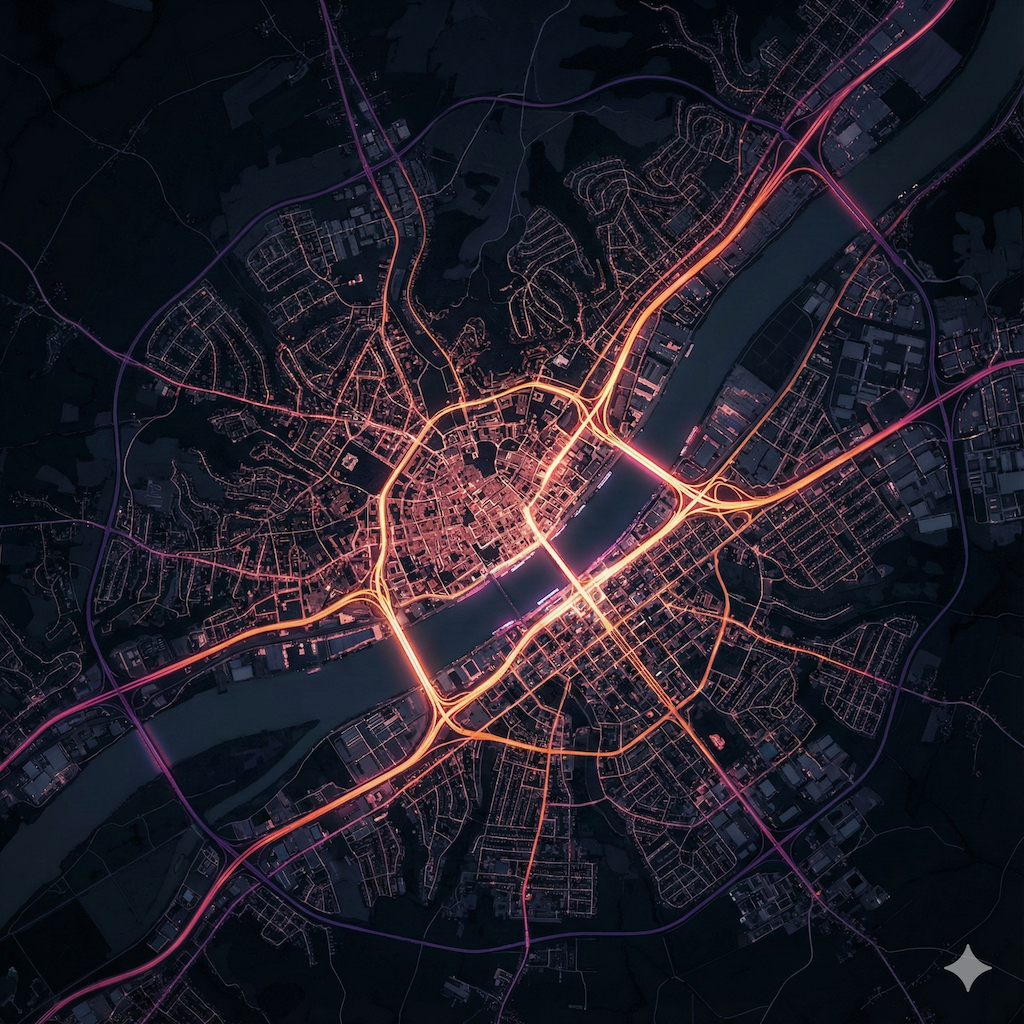
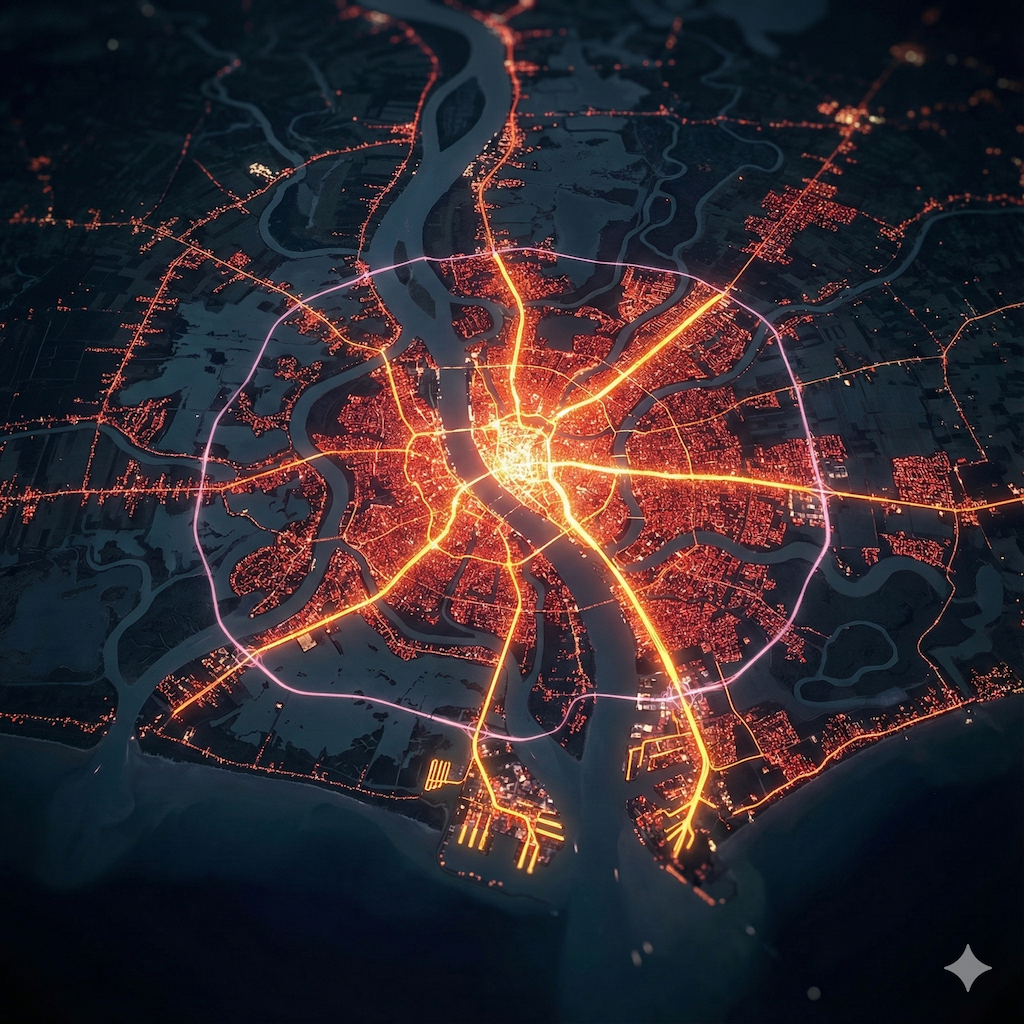
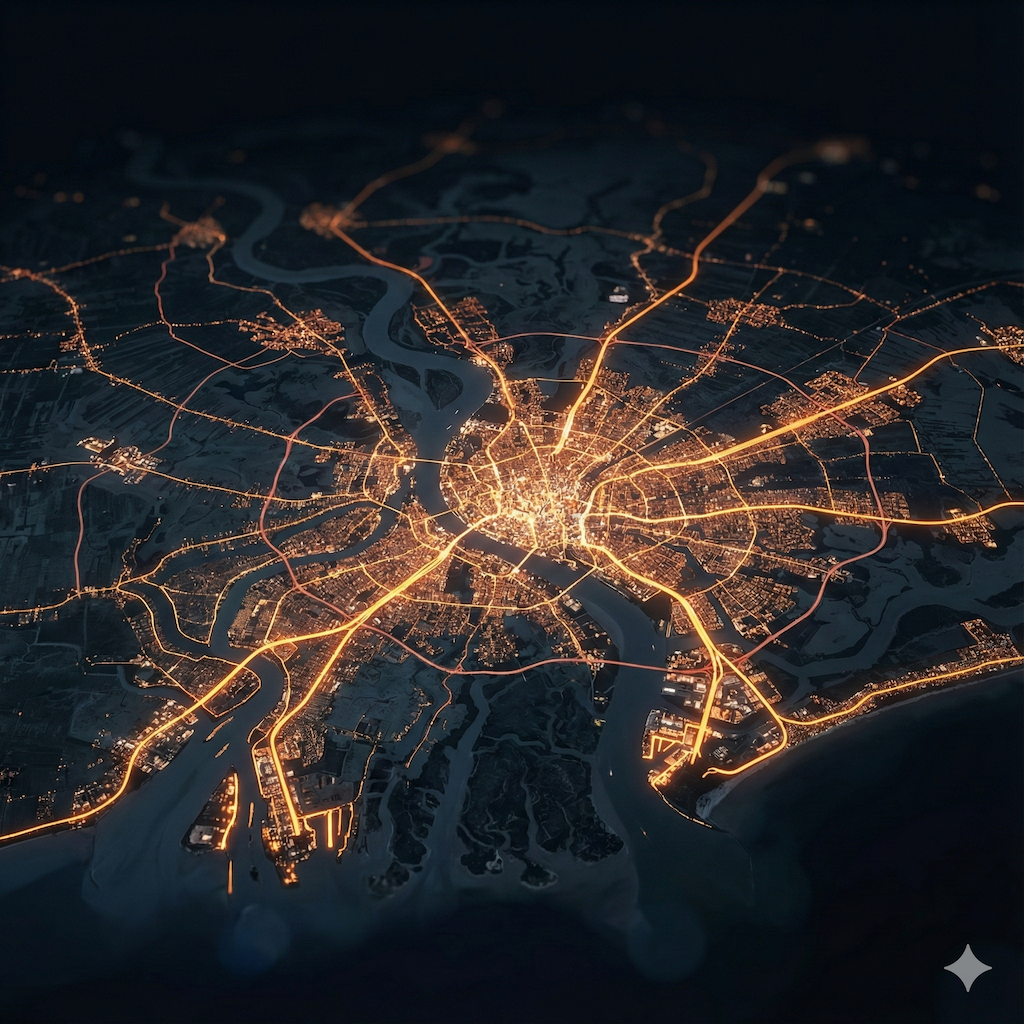
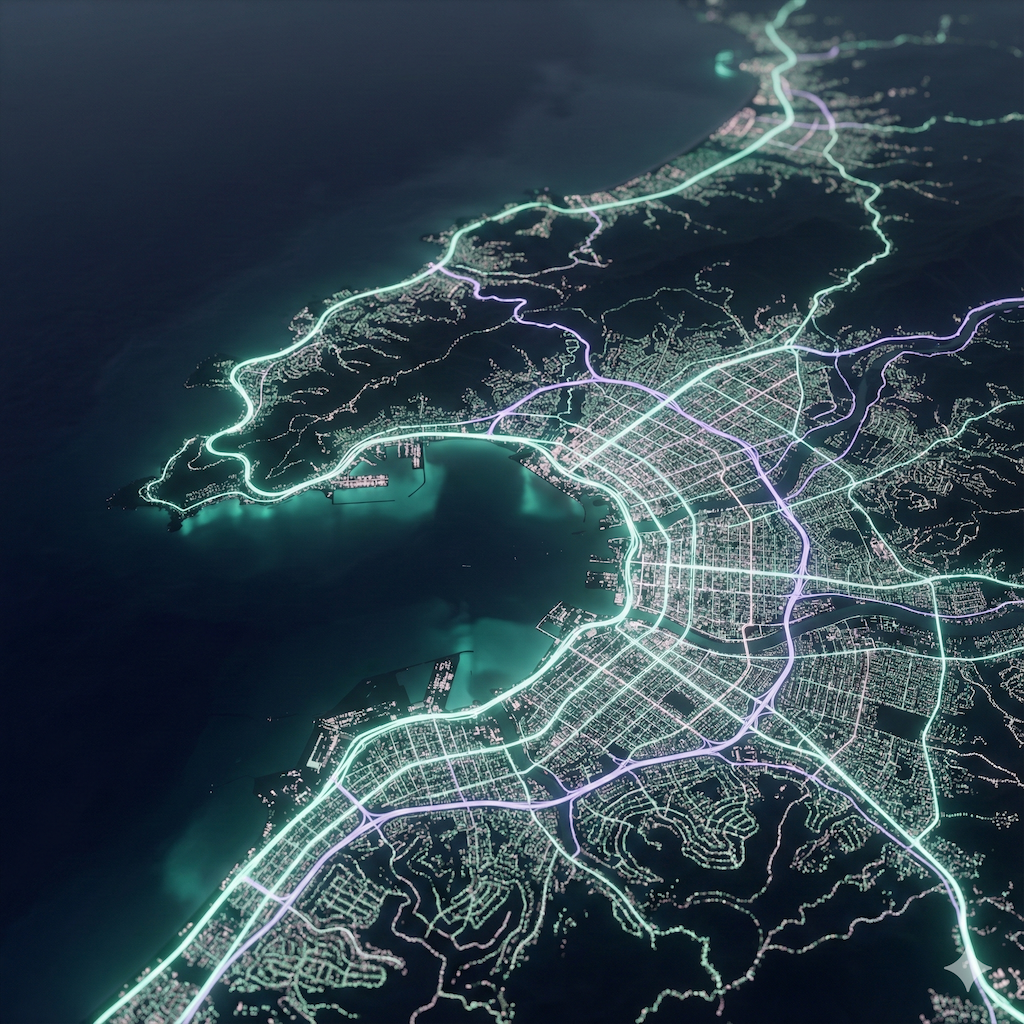
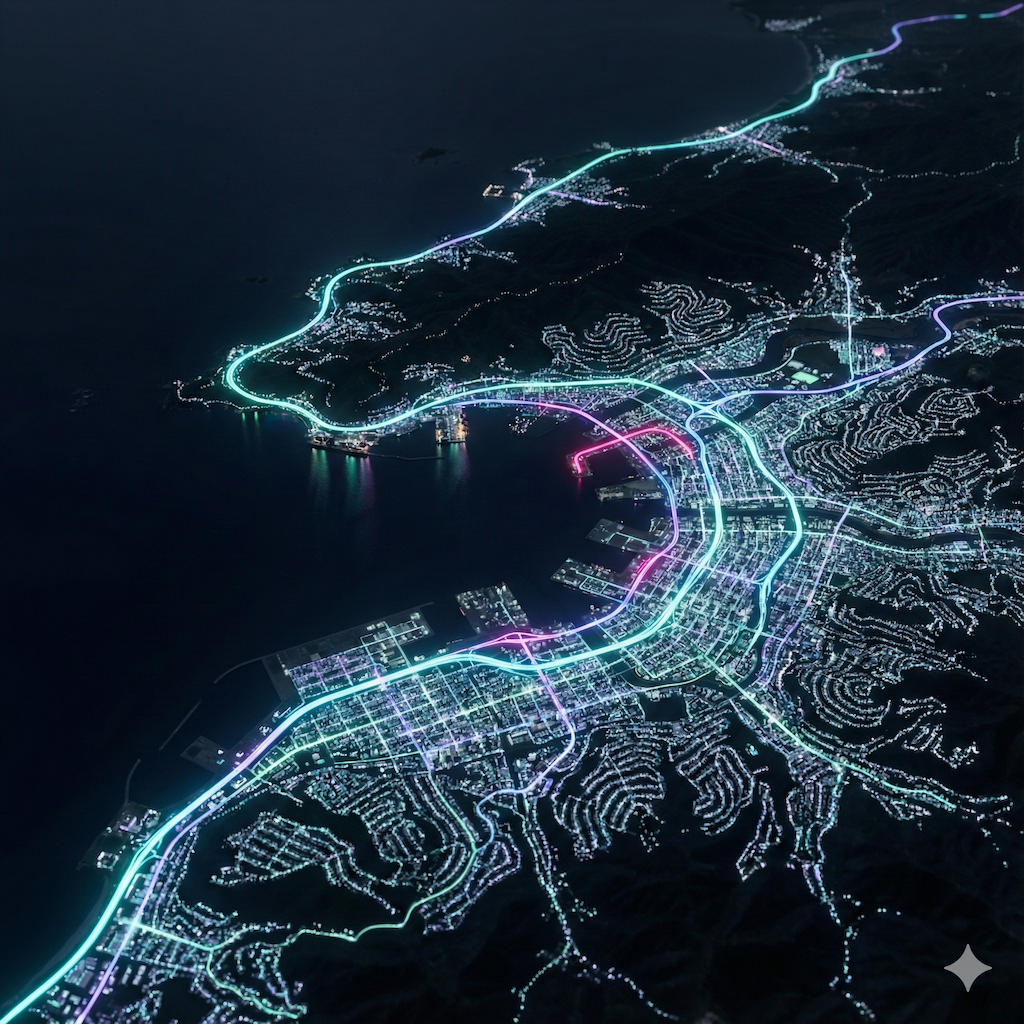















October 2025 - Exploration of SORA2 for creative outputs
Exploration was done both on the SORA website (with trademark on outputs) and later on once APIs we made available through third-party platforms giving access to SORA2 (without trademark on outputs).
While I could have done what most did which was to deep fake themselves in various situations, I decided to try a variety of prompts (hundreds, if not thousands of them) to create a variety of creative and artistic outputs (clubbing, new media art, cyberpunk, creative coding etc).
The model proved to be one of the most creative tool I have used in a long time for pure novel outputs.
The edits below just combined the curated outputs so far in an unordered way.
Prompting was also structured based on timings (12s or 15s outputs) with music/sfx matching the visual cuts as much as possible. It was based on the best prompting practices provided by OpenAI themselves.
More outputs on the SORA website at some of the accounts I created:
https://sora.chatgpt.com/profile/lthevenet
https://sora.chatgpt.com/profile/l_ingenieur
https://sora.chatgpt.com/profile/yo_weirdos
September 2025 - Exploration of Bytedance Seedream image model + Seedance Pro video model
Both Bytedance models are relatively cheap compared to other well known models in the markets. I used Seedream to generate space bodies with some overlayed data lines and structure to test accuracy. This test is artistic first but also about identifying the edge of these models capabilities in terms of these kind of outputs.







July 2025 - Exploration of Bytedance Seedance video model
Seedance is powerful, often very realistic. It can be used for craft exploration as well, which i did in combination with a custom FFMPEG script written in Python to react to the music when curated shots are assembled together. The ratio of shots that are good once the prompt is refined is around 50% which is great.
March 2025 - Early tests with RunwayML Gen4
Mainly b-rolls. Research in prompting for Runway Frames and Runway Gen4 in collaboration with a LLM for refinement, editing and grid creation (ffmpeg) for presentation and analysis.
Feb 2025 - Testing Wan2.1 video training and generation with new media art videos as input datasets
Videos generated were celestial objects of the solar system analyzed and made cinematic like data art would.
This all hypothetical and a test to know the readiness of AI systems in doing something like that out of the box.
June 2024 - Early tests with RunwayML Gen3
July/August 2023 - Early tests with AnimateDiff
Tested on custom Stable Diffusion models long before the hype with AnimateDiff and ControlNet of October/November 2023.
Only 3% of the results were kept (about 30 out of 1K generations).
Generated on a A100 GPU with a custom Jupyter notebook.
August 2023 - Stable Diffusion XL 1.0
Early tests on possibilities of generating materials, textures and fluids.







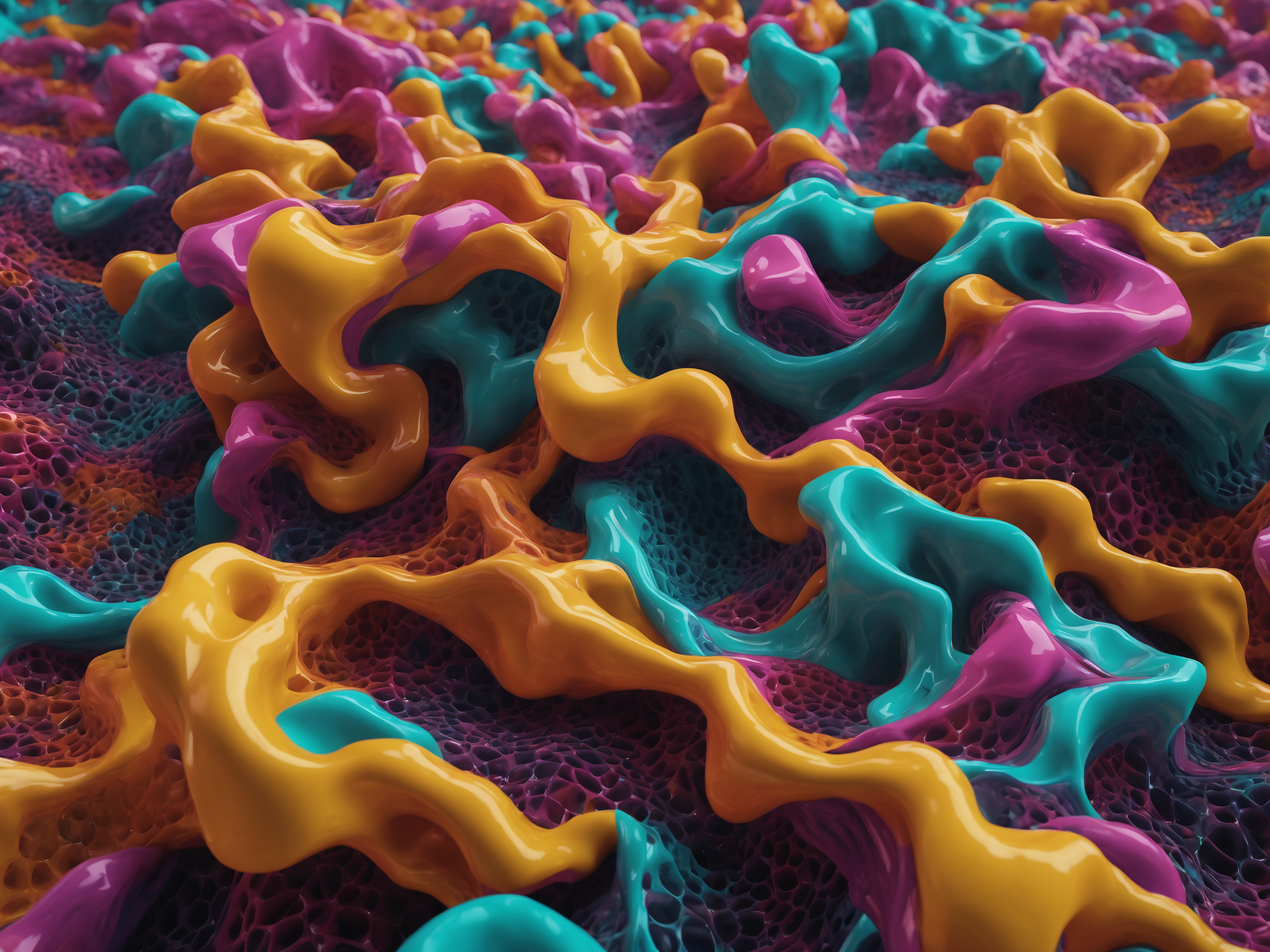


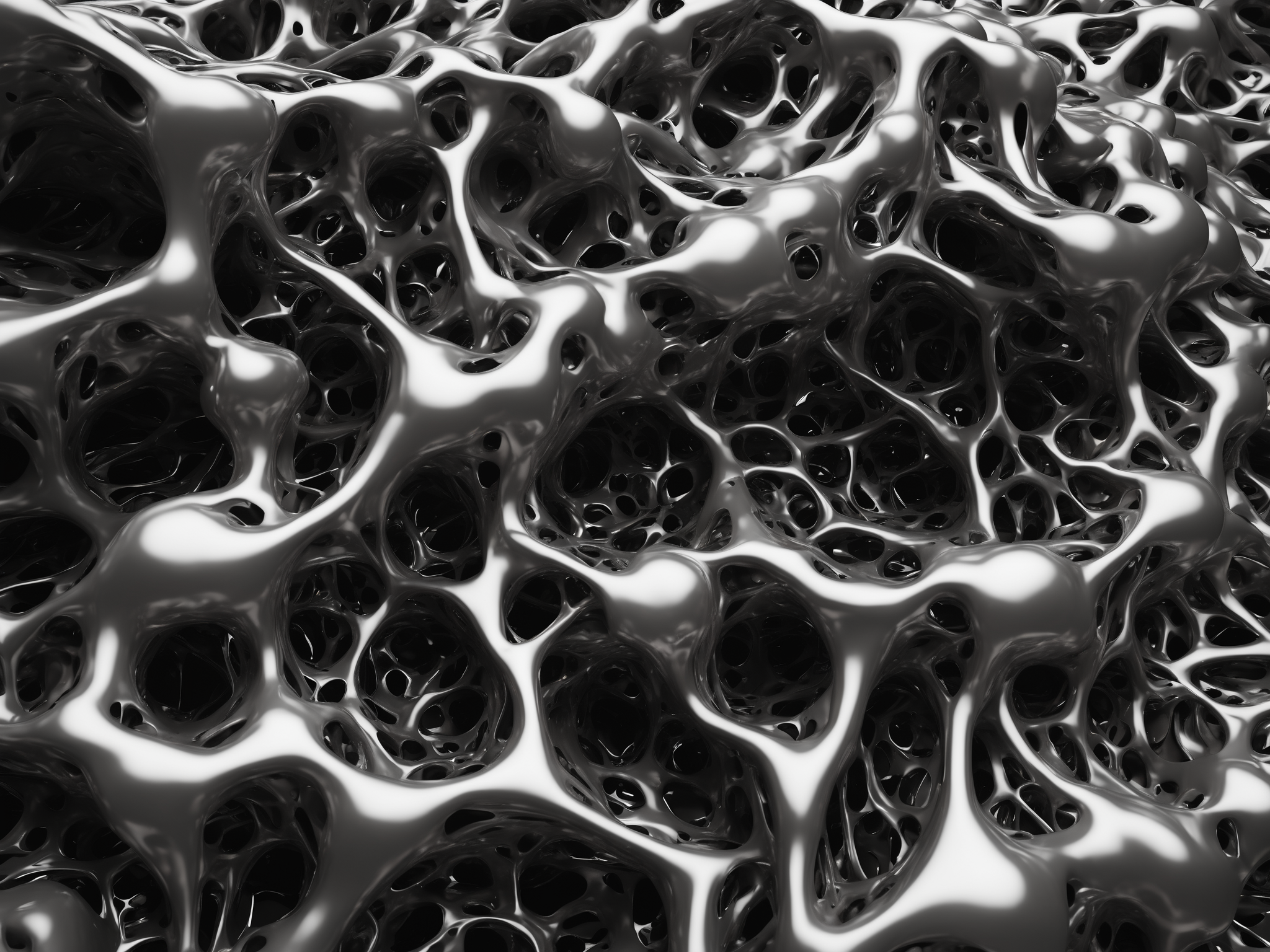




April 2022 - Gen-1 - Organic matter style transfer tests
February 2023 - Detecting synthetics at the Fashion Week
An exploration of hyper-realism with Stable Diffusion, fine-tuned models, ChatGPT and Google Cloud Vision AI.
September 2022 - WarpFusion - Cyberpunk look test over Dubai skyline
September 2022 - WarpFusion - Neo-Makeup
June 2022 - Midjourney - Synthwave sneakers
June 2022 - Midjourney - Super Fake Cars
June 2022 - Midjourney - Future cityscapes + 3D parallax algorithm
Feb 2022 - "Future Cityscapes" (StyleGAN 3)
A creative exercise in which I generate skylines that do not exist, using artificial intelligence. This is the latest WIP output of this side project. It's not perfect but it's starting to look special. This project precedes the GenAI hype and easier generation tools like Midjourney or DALLE.
The machine learning model is trained on a dataset of more than 12,000 images of sci-fi cities. Carefully curated over time, it is now capable of generating that specific "cyberpunk" style.
The first video itself is made out of 32 static images (called "seeds") curated from the hundreds of thousands of visuals that this model can now generate. These images are transitioning in between one another through exactly 345 frames to match the tempo of the track (174BPM) at 60 frames per second. That transition effect, similar to morphing, represent the "latent space" (all the possible variations in between these images). What you see is very much what the machine remembers from having looked at the entire dataset. These are computational memories.
I started this side project in 2020 (see videos and images below), initially training the ML model using #StyleGAN2. I have restarted the training from scratch in December 2021 using #StyleGAN3.
AI for creativity is amazing but it's a passive effort that takes time and $$$ to get anywhere. You can't expect immediate quality with some of these algorithms. To arrive at this (intermediary) result, it took a consolidated 687 hours or about 28 days of a 4 x GPUs setup silently doing its job in the cloud (RTX5000s from JarvisLabs.ai).
Light post-processing was done with SharpenAI and Darkroom.
Dec 2021 - Future Cityscapes v2 (StyleGAN 2)
Collection released as static images on OpenSea: https://opensea.io/collection/future-cityscapes-ai-art-2020-2021

March 2021 - Future Cityscapes v1 (StyleGAN 2)
April 2020 - A Different Energy
A machine learning model (GPT-2) trained on 1,300 sci-fi books and stories available as open-source documents. It was highly experimental but promising.
After a few iterations and fine-tuning, it came up with that story which was then narrated with Google's WaveNet speech synthesizer (+ some reverb in Ableton).
April 2020 - Deep Synths
Synthesizers are a personal passion. I’m both fascinated by the sound they produce and the physics behind it. After feeding a machine with more than 3,000 pictures of old and new synthesizers on white background and training it multiple times over, it finally produced interesting results of synthesizers that don’t exist (yet) but look familiar in shape. The names were also generated using a GPT-2 model trained on historic brands and models.
Tools and algorithms used: RunwayML, StyleGan 2, GPT-2
April 2020 - Retrowave Nuclear Mushrooms
When a machine (StyleGAN2) trained on thousands of vaporwave pictures accidentally ends up drawing Tron-like nuclear #mushrooms.
It's pixellated and this is one of the limitations of creating AI art but who cares, it feels like 1985 again!
It took a lot of patience to make it happen (15K passes so about 16 hours).
January 2020 - Synthesising Singapore traditional food stalls (2020)
Training a machine (StyleGAN) on a few thousands of pictures of Singapore traditional food stalls. After a couple of training and about 10,000 passes, this was the result.

January 2020 - Synthesising Singapore skyline
Training a machine (StyleGAN) on a few thousands of pictures of Singapore skyline. After 4 training and about 15,000 passes, this was the result.

December 2019 - Exploring computer vision algorithms
Exploration of the different computer vision models available in RunwayML to understand their potential and their quality of detection for different visual contexts.



December 2019 - Synthesizing images using segmentation maps
Feeding the SpadeCoco AI algorithm with segmentation maps created out of existing visual assets (using FaceParser or DeepLab) or generative code (P5 JS) as in the video below.